ECHO — agent-orchestrator
Een persoonlijke Jarvis-achtige assistent, solo gebouwd, lokaal draaiend op mijn eigen hardware. Multi-brain LLM-routing, tool-dispatch, vault-backed memory, filesystem-watchers, drie-tier AI-fallback. Ongeveer 24+ Python-modules in de orchestrator, plus een React/Vite-HUD die alles in één dashboard surfacet.
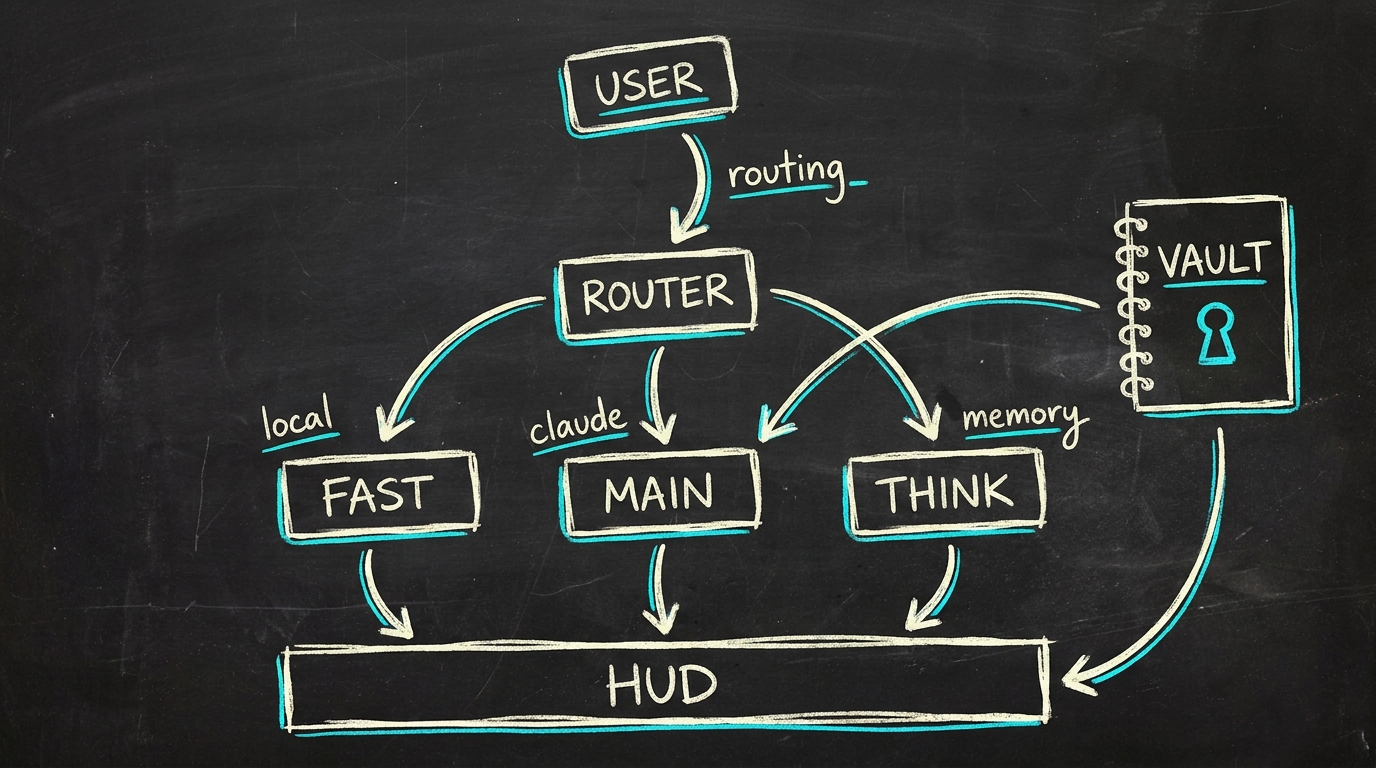
Whiteboard-schets · de vorm van het systeem
Wat ECHO in de praktijk doet
Ik praat met haar, zij praat terug. Maar het interessante zit niet in de chat. Het zit in wat er tussen turns gebeurt. ECHO observeert mijn filesystem, de recente commits over al mijn projecten, de open nudges in mijn vault, en synthetiseert dat tot ochtend-briefings, code-change-chronicles, time-tracking-aggregaten, en proactieve interventies als er iets niet klopt.
Concreet, in één turn kan ECHO:
- Beslissen welke model-tier ze gebruikt (
fast/main/think/local) op basis van de vorm van de request - Een tool dispatchen (vault-search, database-query, shell-command, KPI-pulse van een aangesloten product)
- Gestructureerde JSON updaten voor een persoonlijke dashboard
- Een notitie aan een lopende time-entry hangen zonder de timer te stoppen
- Een memory-worker triggeren die de daily-note van gisteren consolideert
De HUD laat alles zien: een "Brain Waves" trace, een token-burn-meter, een vault-graph, een CC-status-indicator, en project-specifieke panels (deels redacted in deze publieke versie).
Architectuur
┌─────────────────────────────────────────────────────────────┐
│ HUD (React + Vite) │
│ Presence · Vitals · TokenBurn · VaultGraph · Project │
│ panels · RailTabs · Identity │
└──────────────────────────────┬──────────────────────────────┘
│ HTTP polling + SSE
▼
┌─────────────────────────────────────────────────────────────┐
│ Orchestrator (FastAPI · Python 3.13) │
│ ───────────────────────────────────────────────────────── │
│ router.py — Multi-brain selection (heuristics + LLM) │
│ tools.py — 14+ tool dispatch │
│ skills.py — agentskills.io-compatible workflow layer │
│ vault_graph.py — Markdown vault + Wikilink edges │
│ time_track.py — Time entries, urencriterium, exports │
│ runway.py — Personal-finance runway dashboard │
│ social.py — Social-media accounts registry │
│ cc_status.py — Claude Code activity from JSONL │
│ ... + nudges, agenda, hue, intents, voice, tts, en een │
│ handvol product-specifieke integratie-modules │
└──────┬──────────────────────────────┬───────────────────────┘
│ │
▼ ▼
┌──────────────────┐ ┌────────────────────────────────┐
│ Memory Worker │ │ External LLMs │
│ (APScheduler) │ │ ───────────────────────────── │
│ ────────────── │ │ Anthropic (Claude API) │
│ Drafter │ │ Ollama local (Qwen, Llama) │
│ Curator │ │ ComfyUI local (Stable Diff) │
│ Consolidator │ │ │
│ Watchers │ │ 3-tier fallback: │
│ Reflector │ │ API → rules → hardcoded │
│ Daily-summary │ │ │
└──────────────────┘ └────────────────────────────────┘
De multi-brain router
De router bepaalt welke model-tier wordt aangesproken voordat de request de orchestrator verlaat. Eerst goedkope heuristieken, dan pas een LLM-classifier als die het niet weten.
async def decide(text: str, *, force: Brain | None = None) -> RouterDecision:
if force is not None:
return RouterDecision(force, "manual", "user-override")
# Goedkope regex-heuristieken eerst
h = _heuristic(text)
if h is not None:
return h
# Fallback op een klein model als classifier
return await _llm_classify(text)
Vier heuristiek-lagen draaien op volgorde: triviale-groet (sub-seconde
antwoorden gaan naar fast), business-keyword (alles wat een
project-context raakt gaat naar main zodat de juiste system-prompt
laadt), deep-keyword (architectuur / code-review naar think), en
shell-keyword (filesystem-vragen naar main waar shell-tools
beschikbaar zijn).
Die laatste laag doet meer dan je denkt: kleine modellen schrijven
PowerShell-commands routinematig uit als Markdown-block in plaats van
de shell-tool aan te roepen. Die queries naar main routeren fixt de
failure-mode aan de bron.
Tool-dispatch + skills-laag
ECHO biedt ~14 tools aan via het tool-use-protocol:
vault_read, vault_search, shell_check, list_skills /
run_skill, time_start / time_stop, time_summary,
note_learning, en een handvol product-specifieke tools.
De skills-laag is agentskills.io-compatibel: elke skill leeft op
memory/_skills/<skill-name>/SKILL.md met YAML-frontmatter voor
metadata en Markdown-body voor het recept. list_skills is goedkoop
(retourneert alleen frontmatter); run_skill(name) laadt de volledige
body en ECHO volgt de genummerde stappen, callt de tools in de juiste
volgorde.
Invocation-count, success-rate, en last-used-timestamp updaten zichzelf in de frontmatter. Slow telemetry, geen aparte database.
Vault-backed memory
Het geheugen van ECHO is een Markdown-vault met WikiLink-edges. De vault
heeft folders voor People, Projects, Daily-notes, Knowledge, Tasks, en
System. De graph wordt live geparsed door vault_graph.py en gerenderd
in de HUD als 3D force-directed visualisatie met folder-clustering.
Wat er in de vault leeft: mijn eigen notities, een inbox waar ECHO
voorgestelde nudges in dropt, daily-notes die de consolidator schrijft,
een chronicle van elke Claude Code-commit over al mijn projecten, en
een CC-inbox.md-kanaal waar dev-Claude ECHO tussen turns kan briefen.
De watchers — Python-jobs gescheduled door APScheduler — monitoren commits, sentry, issues, project-state, agenda, idle. Elk emit een gestructureerde trigger als het iets ziet dat ECHO's aandacht waard is; de drafter maakt van triggers proposed nudges; de curator aggregeert periodiek.
Drie-tier AI-fallback
ECHO neemt nooit aan dat de API up is. Drie tiers:
- Tier 1 — API (primair, hoogste kwaliteit)
- Tier 2 — Rule-based reasoning (fallback als de API down of rate-limited is; minder vlot, maar nog steeds zinnig)
- Tier 3 — Hardcoded (offline minimum-viable response)
Dit patroon komt op meerdere lagen terug. Resultaat: ECHO blijft werken ook als externe services dat niet doen.
Lokale AI-infrastructuur
ECHO draait lokaal op mijn main werkplek: Ryzen 7 3700X met AMD RX 6650 XT (8GB), Windows. De orchestrator, de HUD, de vault, de watchers en drafters, en ComfyUI voor image-generation draaien allemaal op dezelfde box. Een oudere AMD-machine staat ernaast als Linux-testbed voor side-projects, niet als onderdeel van het productie-ECHO-pad.
Voor zwaardere inference (grotere context-windows, model-fine-tuning, batch-image-werk) val ik terug op remote-toegang naar een meer capabele GPU-setup via TeamViewer of een direct port-forward.
Lokale LLMs draaien via Ollama (Qwen 2.5 7B, Llama 3.2 3B) voor routing, classificatie, en alles waar de API niet nodig is. De Anthropic Claude API is gereserveerd voor complex redeneerwerk waar lokale modellen de kwaliteit niet halen. Het meeste routine-werk draait op de main box; cloud-kosten blijven bescheiden.
Privacy-filter
De vault wordt elke turn in ECHO's persona geladen. Alles wat erin staat wordt dus door de LLM gelezen en naar de API gestuurd. Een privacy-filter draait op elk write-entry-point (drafter, curator, extractor, commit-chronicles, daily-summarizer) en redact een kleine set lokaal-gevoelige programma-namen naar een generieke token. Filter aan de write-kant; de read-kant blijft simpel.
Autonome lagen
ECHO is in lagen opgebouwd, elk progressief autonomer:
- Geheugen-laag — Obsidian-vault met WikiLink-edges, gevoed door elk gesprek, beslissing en commit. Markdown, geen lock-in, leesbaar los van ECHO.
- Watchers — Python-jobs op APScheduler die filesystem-events, git-commits, calendar-pings en sentry-issues monitoren en gestructureerde triggers emitten.
- Drafters — cron-jobs voor weekly recap, daily summary, time-tracking aggregaat en vault-consolidation. Output landt als proposed nudges in een inbox voor review.
- Sleep-time-compute (in ontwikkeling) — goedkoop model dat 's nachts nieuwe vault-entries leest en verbanden voorstelt.