CaptionCompass — die Wörter sehen, spüren, woher sie kommen
Eine caption-first Accessibility-App für gehörlose und schwerhörige Android-Nutzer. Live-Untertitel sind immer sichtbar. Ein grober Richtungshinweis zum Sprecher erscheint nur dann, wenn er zuverlässig ist.
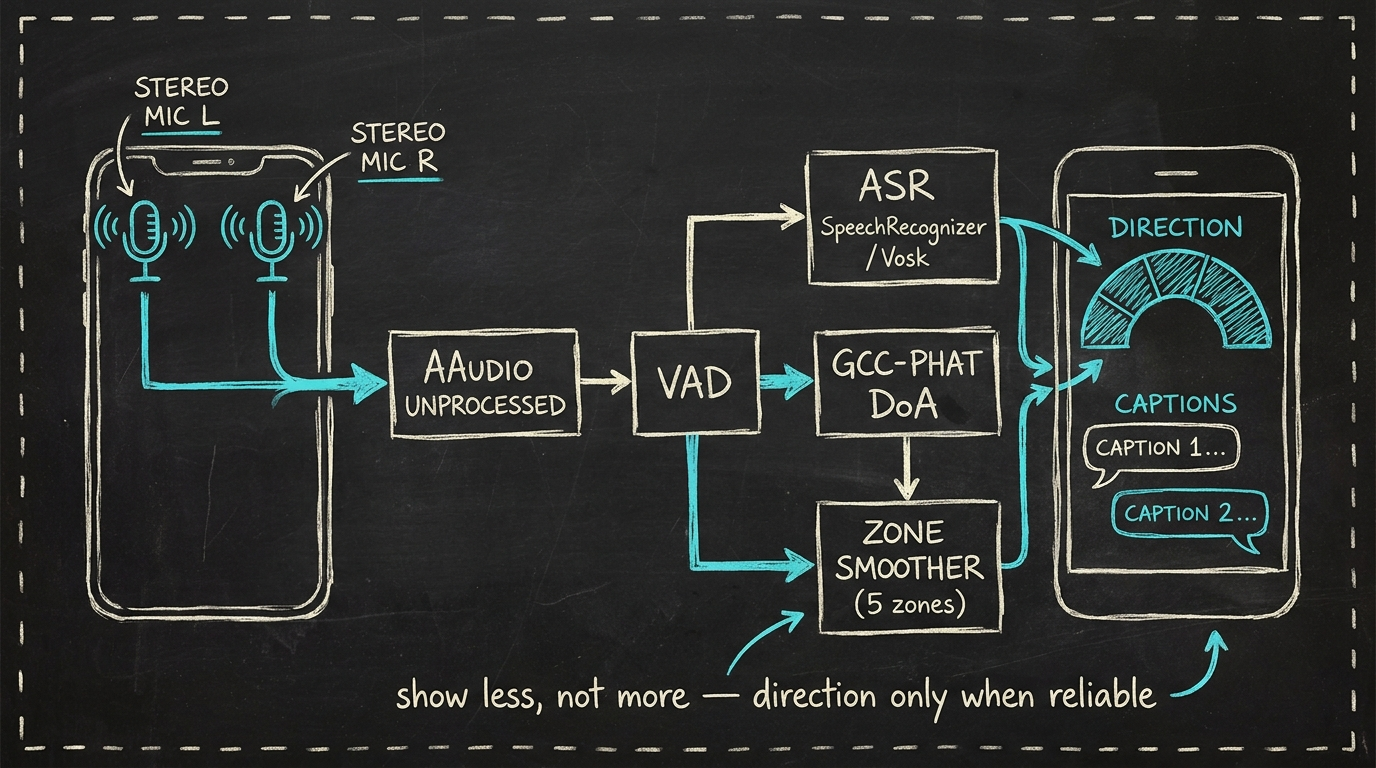
Whiteboard-Skizze · die Audio-Pipeline
Die Produktphilosophie in fünf Sätzen
Der Richtungshinweis ist opt-in und gated. Er erscheint nur, wenn:
- Der Nutzer ihn in den Einstellungen aktiviert hat, und
- Das Gerät zwei brauchbare Mikrofone über die UNPROCESSED-Audioquelle bereitstellt, und
- Das Telefon flach und ruhig liegt (Gyroskop-Check), und
- Die Confidence hoch oder mittel ist.
Fällt eine dieser Bedingungen weg, funktionieren die Untertitel unverändert weiter und der Richtungs-Arc blendet aus. "Show less, not more" — kein Feature abschalten, sondern das Feature respektvoll zurücknehmen, wenn es sich nicht hart genug belegen lässt.
Was im MVP steckt
| Schicht | Status |
|---|---|
| Projekt / Gradle / Manifest | ready |
| Domänenmodell + Fallback-Policy | ready, unit-tested |
| Capability-Probe (sucht nach UNPROCESSED + Stereo) | ready |
AudioRecord Stereo-Capture | ready |
| Energy-VAD (Voice Activity Detection) | ready |
| GCC-PHAT DoA + Zone-Smoother | ready, unit-tested für τ→Zonen-Mapping |
Android SpeechRecognizer-Adapter | ready |
| Mock-Audio + Mock-ASR (für Emulator-Arbeit) | ready |
| Foreground-Service (Android 14 Mic-Type) | ready |
| Compose-UI (Statusleiste, Direction-Arc, Untertitel, Controls) | ready |
| Phase 2 | Vosk-Fallback-ASR, Silero-VAD ONNX |
| Phase 4 | Stereo-BLE-Input (externe Stereo-Mikrofone) |
Stack
AudioRecord mit UNPROCESSED-Source und Stereo-Channel-MaskSpeechRecognizer (online), Vosk (Phase 2, Offline-Fallback)microphone Foreground-TypeWarum GCC-PHAT und kein ML-Modell für die Richtung
DoA mit zwei Mikrofonen ist ein gelöstes mathematisches Problem, wenn man es korrekt framt. GCC-PHAT liefert eine Time-Difference-of-Arrival, aus der sich ein einziger Azimut ergibt. Auf einem Telefon mit ~14cm zwischen den Mikrofonen ergibt das keine gradgenaue Präzision, aber sehr wohl eine zuverlässige Links- / Mitte- / Rechts- / Hinten-links- / Hinten-rechts-Indikation (fünf Zonen). Das reicht für den Anwendungsfall aus, ohne ML-Modelle, die Latenz und Akku kosten.
Für die Confidence-Bewertung wird die Schärfe des Cross-Correlation-Peaks herangezogen — ein hoher Peak bedeutet eine klare Quelle; ein flacher Peak bedeutet mehrere Sprecher oder Rauschen, und dann wird der Arc ausgeblendet, statt eine irreführende Richtung anzuzeigen.
Status + Roadmap
Jetzt: MVP-Scaffold ready. Domänenschicht unit-tested, Compose-UI
läuft, Stereo-Capture funktioniert, Untertitel funktionieren über
SpeechRecognizer. Mock-Modus für die Emulator-Entwicklung.
Phase 2: Vosk Offline-ASR + Silero-VAD ONNX (bessere VAD, geräteunabhängig).
Phase 4: Stereo-BLE-Input — externe Stereo-Mikrofone über Bluetooth anschließen für bessere DoA-Präzision als die eingebauten Telefon-Mikrofone.