agentskills.io implementation
Tools are atomic. Skills are recipes. A tool reads a file, runs a query, fetches a URL. Skills are named multi-step procedures that combine several tools with reasoning steps in a fixed order. The agentskills.io standard defines what a skill looks like, and building it into a tool-using agent is a small change that pays off quickly.
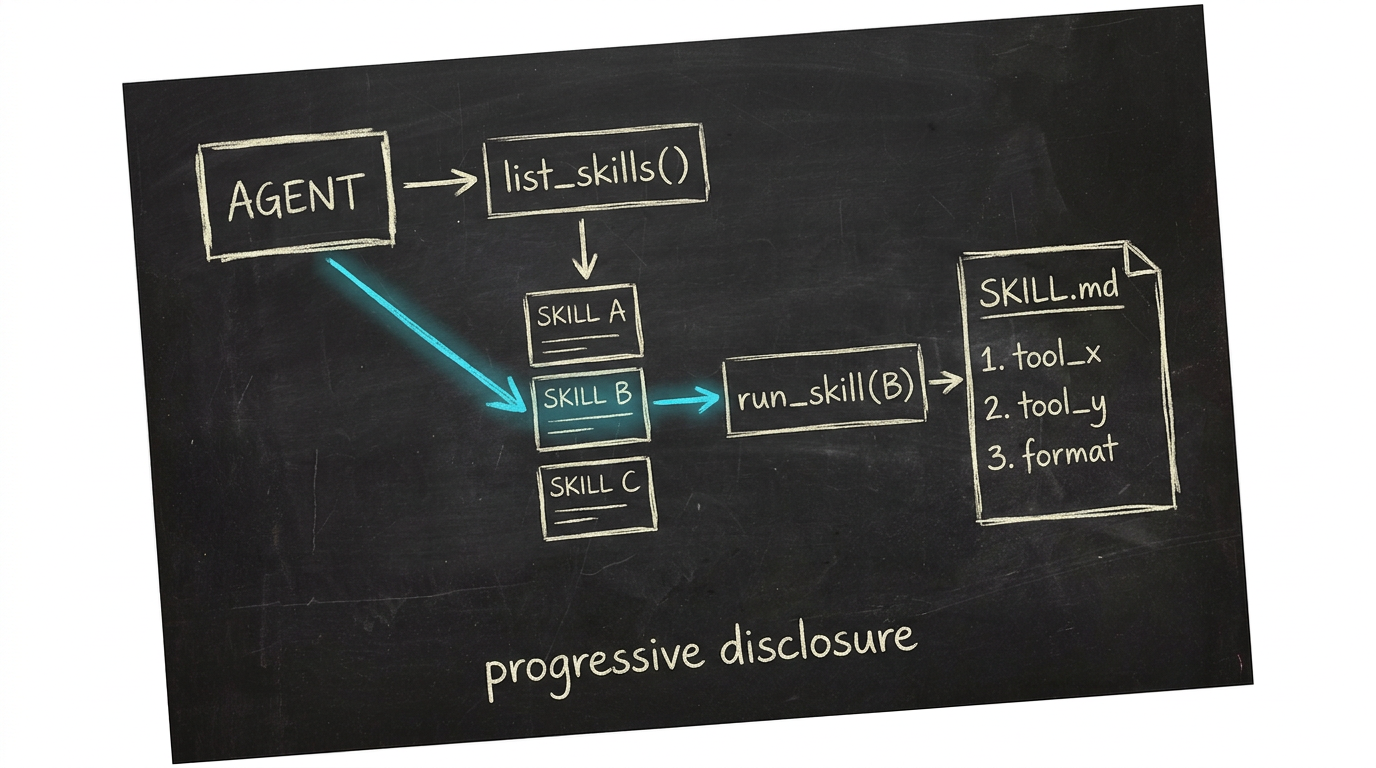
Whiteboard sketch · progressive disclosure
Why a skills layer on top of tools
After 50 turns with a tool-using LLM you start to notice a pattern: the same multi-tool workflows get reinvented every time, with small variations. "Morning status" calls the same five tools in roughly the same order, but the formatting drifts. "Weekly recap" is a similar shape but worse — more tools, more places to deviate.
The fix: a skills layer. Every recurring workflow becomes a named recipe; the LLM looks the recipe up instead of replanning from scratch every time.
Three concrete wins:
- Consistency. The same kind of request produces the same shape of output. Important for things you read repeatedly (daily briefings, reports).
- Less reasoning per turn. The LLM doesn't have to replan a known workflow; it follows the steps. Cheaper, faster.
- Maintainability. Want to change "how morning briefings work"? Edit one file, not the model's prompt.
SKILL.md format
The agentskills.io spec is minimal. A skill is a directory with a
SKILL.md file (optionally with subfolders for scripts, references,
assets). The SKILL.md has YAML frontmatter and a Markdown body:
---
name: daily-status-report
description: "Compile yesterday's commits, today's calendar, open
nudges into a single morning briefing. Use when Nathan asks for a
status report or starts a new conversation after >6h silence."
---
# Daily status report
Run the tools below in order, then synthesise the markdown summary at
the bottom.
## Steps
1. Call `commit_log` for yesterday's commits across all projects
2. Call `calendar_today` for events
3. Call `nudges_open` for pending review items
4. Format the output as:
- "Yesterday: <commits>"
- "Today: <events>"
- "Awaiting review: <nudges>"
Two mandatory frontmatter fields: name (matching the
directory name) and description (max 1024 characters — this is what the LLM
sees when choosing a skill).
Progressive disclosure
The key design choice: only the metadata (frontmatter) is loaded into the LLM context at startup. The full body is loaded only once the LLM decides to invoke a specific skill. Two tools support that:
def list_skills() -> list[dict]:
"""Cheap: returns name + description for all skills."""
return [parse_frontmatter(p) for p in glob("memory/_skills/*/SKILL.md")]
def run_skill(name: str) -> dict:
"""Loads full SKILL.md body. ~5000 token budget per spec."""
return read_skill(name)
list_skills costs ~100 tokens per skill — cheap enough to call every turn
or to put in the system prompt. run_skill is the expensive
operation, only called once the LLM has chosen a specific skill.
This pattern keeps context size manageable, even when you have 50+ skills available.
How the LLM uses it
In practice the prompt loop becomes:
- User: "give me a morning status"
- LLM (with
list_skillsalready in context): recognizes that this matches the description ofdaily-status-report - LLM calls
run_skill("daily-status-report") - LLM receives the full body, follows the steps, calls the tools in the right order
- LLM formats according to the template in the skill
The LLM still does reasoning (which skill matches, how to handle edge cases), but the plan is canonical. Same request, same shape of output.
When to add a skill
Heuristic: the moment you write out the same multi-step workflow to the LLM three times, turn it into a skill. Authoring takes ~15 minutes; the return is permanent.
Bad candidates for a skill:
- One-off requests (just let the LLM plan)
- Single-tool calls (a skill is overkill)
- Highly variable workflows (every invocation has different steps)
Good candidates:
- Status / briefing / recap reports
- Multi-tool diagnostics ("check why X is failing")
- Onboarding sequences ("set up a new project")
- Anything that runs on a schedule
Auto-tracking usage
The frontmatter can store invocation counts and success rates over
time. Each run_skill call appends a counter at the bottom of the
frontmatter:
total_invocations: 47
total_successes: 45
success_rate: 0.957
last_used: "2026-06-02T08:30:22Z"
Slow telemetry — file-based, no separate database. But enough to see which skills pull their weight and which never get used. Unused ones: throw away. Popular ones: deepen.
Why agentskills.io specifically
It's the spec Anthropic adopted for Claude Skills. Using it means your skills are portable: they work in your local orchestrator, they work in Claude.ai, they work in any tool-using agent that supports the standard. You can also borrow community skills without rewriting them.
The standard is small enough to read through in 10 minutes. The investment to adopt it is small enough to be a one-afternoon refactor. The payoff is permanent.