Real-time audio in Rust
Audio callbacks have a hard deadline. At 48kHz with a 256-sample buffer, the audio thread gets ~5 milliseconds to produce the next chunk. Miss it, and the user hears a click, a gap, or a dropout. That constraint shapes everything that happens underneath.
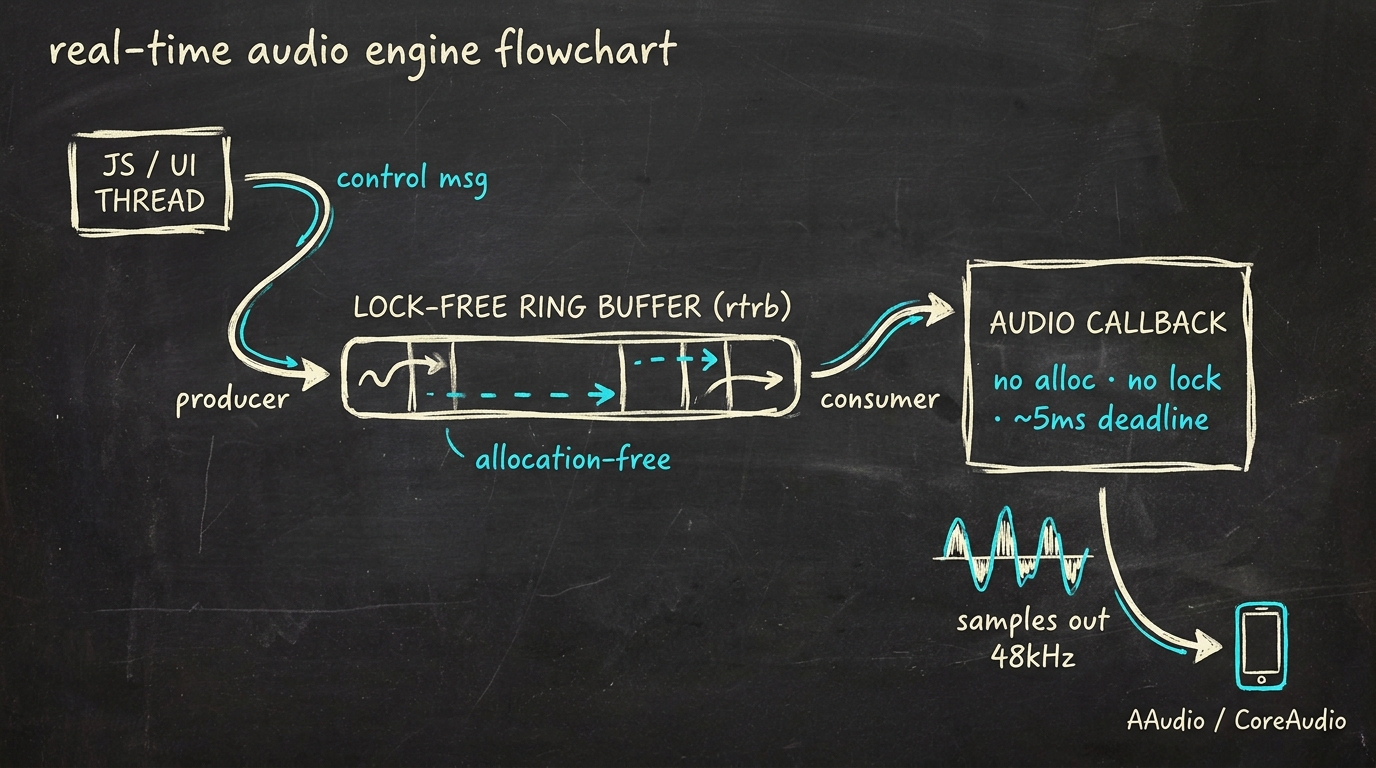
Whiteboard sketch · the shape of the engine
Rust is a good fit for this work — once you set aside most of the standard
library. The borrow checker prevents data races at compile time, but a
single Box::new on the audio path will still wreck your latency. The
patterns below are what make it work in practice.
The setup
A typical mobile audio app has three threads that matter:
- JS / UI thread — captures user input, sends control messages
- Native dispatch thread — translates those messages, runs business logic, keeps state
- Audio callback thread — runs inside the OS audio subsystem (AAudio on Android, CoreAudio on iOS), invoked with strict timing
The audio callback thread must never block, never allocate, never wait on a mutex. When the JS thread changes a parameter (volume, FX bypass, whatever), that change has to reach the audio thread without the audio thread ever having to wait.
That's the core problem. The lock-free SPSC ring buffer is the solution.
Lock-free SPSC via rtrb
A single-producer, single-consumer ring buffer is the simplest lock-free
data structure that works here. One thread writes, another reads, neither
blocks. The Rust crate rtrb (real-time ring buffer) implements this
with the right atomic semantics:
use rtrb::{Consumer, Producer, RingBuffer};
// Setup (once, outside the audio thread)
let (mut producer, mut consumer): (Producer<ControlMsg>, Consumer<ControlMsg>) =
RingBuffer::new(256).split();
// JS / dispatch thread — non-blocking push
producer.push(ControlMsg::SetVolume { track: 0, value: 0.8 })
.expect("ring buffer full");
// Audio callback — non-blocking pop, drain everything in the queue
while let Ok(msg) = consumer.pop() {
apply_message(&mut state, msg);
}
The audio callback drains the buffer at the start of every block, applies the control changes, and then processes audio. No locks, no waits, no allocations.
If the producer side is faster than the consumer drains, the buffer fills
up and push returns an error. That's exactly your signal: either the
buffer is too small, or the consumer is dropping frames. You catch both at
runtime; neither corrupts the audio.
Allocation-free audio path
The other discipline is harder to enforce: zero heap allocations during audio callbacks. That means:
- No
Box::new, noVec::new, noString::from - No
format!(), no logging (most logger macros allocate) - No JSON deserialization (or anything similar) on the audio thread
- No iterator chains that allocate intermediate
Vecs - No async / await (the executor allocates and yields, both bad)
The pattern: pre-allocate everything during setup, reuse buffers on the
audio thread. A Vec<f32> with samples_per_block capacity, allocated
once before the audio engine starts, overwritten in place on every
callback.
Rust's ownership model helps here — once you've internalized the
pattern of "code without Box/Vec/String allocations," the compiler
keeps you honest. The pattern carries over from project to project.
FFI surface
The audio engine compiles to a static library. The app (in my case React Native) calls into the engine through an FFI layer. Two design choices that matter:
1. Keep the FFI surface small. Every FFI function is a maintenance burden — both languages have to agree on memory layout, lifetime, error handling. I aim for ~10-15 FFI functions that wrap the engine's public API; anything beyond that stays internal on the Rust side.
2. Pass opaque pointers. Don't try to share Rust structs across the
C ABI. Allocate the struct in Rust, return a *mut OpaqueState pointer,
and have every subsequent FFI call hand that pointer back. The caller never
looks inside it; the Rust side owns the layout. Cleanup is a single
drop_state(*mut OpaqueState) FFI call.
Cross-platform reality
Android AAudio behaves differently from iOS CoreAudio. Buffer sizes that work on one device don't work on another. OEM Android builds (Samsung, OnePlus, Xiaomi) each have their own edge cases. The practical answer:
- Pin a known-good NDK version
- Test on at least three OEM devices, ideally including a budget chip
- Build for arm64 first; armv7 and x86_64 are derivatives but must work in case an OEM uses them
- Build a fallback path: if AAudio refuses your requested buffer size, fall back to the device preference and log a warning
An audio engine that's correct on its own still doesn't work on every device. A real test bench matters more than synthetic benchmarks.
What this enables
Once the audio path is allocation-free and the control path is lock-free, you can build up layers: multi-track playback, per-track FX chains, sample-accurate scheduling, MIDI control. The baseline discipline doesn't get heavier; you just get more nodes in the graph.
Latency stays sub-20ms on consumer Android hardware. That's the threshold below which most people feel "instant." Above 20ms you feel the lag. Below 20ms you start competing with desktop DAWs on the basic feel.