Audio temps réel en Rust
Les callbacks audio ont une deadline dure. À 48kHz avec un buffer de 256 samples, le thread audio dispose d'environ 5 millisecondes pour produire le prochain chunk. Si tu la rates, l'utilisateur entend un clic, un trou ou un dropout. Cette contrainte façonne tout ce qui se passe en dessous.
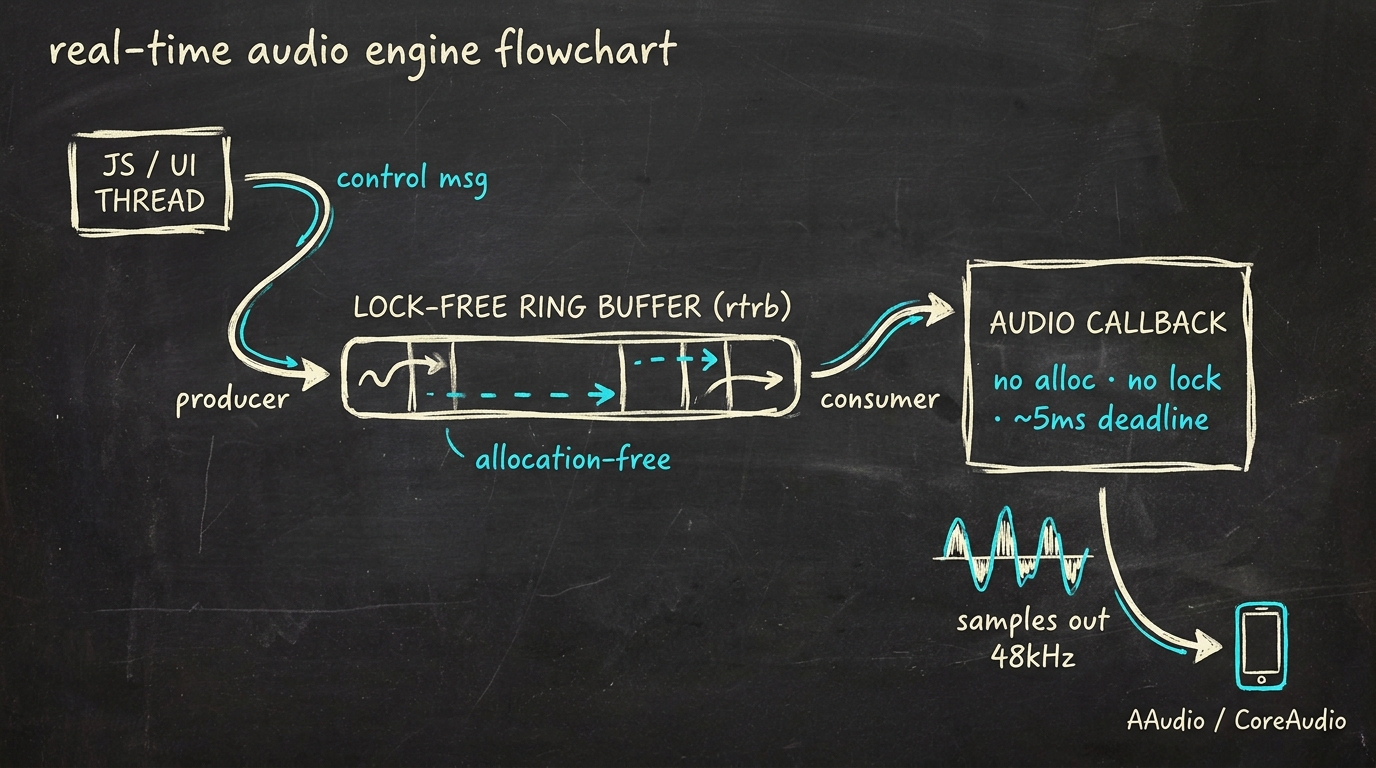
Croquis whiteboard · la forme du moteur
Rust convient bien à ce travail — dès que tu laisses de côté la majeure
partie de la standard library. Le borrow checker empêche les data races à
la compilation, mais un seul Box::new sur le chemin audio ruine quand
même ta latence. Les patterns ci-dessous sont ce qui le fait fonctionner
en pratique.
Le setup
Une app audio mobile typique a trois threads qui comptent :
- Thread JS / UI — capte l'input utilisateur, envoie les messages de contrôle
- Thread de dispatch natif — traduit ces messages, exécute la logique métier, conserve l'état
- Thread du callback audio — tourne dans le sous-système audio de l'OS (AAudio sur Android, CoreAudio sur iOS), appelé avec un timing strict
Le thread du callback audio ne doit jamais bloquer, jamais allouer, jamais attendre sur un mutex. Quand le thread JS modifie un paramètre (volume, bypass FX, peu importe), cette modification doit atteindre le thread audio sans que le thread audio ait jamais à attendre.
C'est le problème central. Le ring buffer SPSC lock-free est la solution.
SPSC lock-free via rtrb
Un ring buffer single-producer, single-consumer est la structure de
données lock-free la plus simple qui fonctionne ici. Un thread écrit, un
autre lit, aucun ne bloque. La crate Rust rtrb (real-time ring buffer)
l'implémente avec la bonne sémantique atomique :
use rtrb::{Consumer, Producer, RingBuffer};
// Setup (une fois, en dehors du thread audio)
let (mut producer, mut consumer): (Producer<ControlMsg>, Consumer<ControlMsg>) =
RingBuffer::new(256).split();
// Thread JS / dispatch — push non bloquant
producer.push(ControlMsg::SetVolume { track: 0, value: 0.8 })
.expect("ring buffer full");
// Callback audio — pop non bloquant, vide tout ce qui est dans la queue
while let Ok(msg) = consumer.pop() {
apply_message(&mut state, msg);
}
Le callback audio vide le buffer au début de chaque block, applique les changements de contrôle, puis traite l'audio. Pas de locks, pas d'attente, pas d'allocations.
Si le côté producer est plus rapide que le consumer ne vide, le buffer se
remplit et push renvoie une erreur. C'est précisément ton signal : soit
le buffer est trop petit, soit le consumer drop des frames. Tu attrapes les
deux à l'exécution ; aucun des deux ne corrompt l'audio.
Chemin audio sans allocation
L'autre discipline est plus difficile à imposer : zéro allocation sur le heap pendant les callbacks audio. Cela signifie :
- Pas de
Box::new, pas deVec::new, pas deString::from - Pas de
format!(), pas de logging (la plupart des macros de logger allouent) - Pas de désérialisation JSON (ou équivalent) sur le thread audio
- Pas de chaînes d'itérateurs qui allouent des
Vecintermédiaires - Pas d'async / await (l'executor alloue et yield, les deux sont mauvais)
Le pattern : tout pré-allouer au setup, réutiliser les buffers sur le
thread audio. Un Vec<f32> de capacité samples_per_block, alloué une
seule fois avant le démarrage du moteur audio, réécrit in-place à chaque
callback.
Le modèle d'ownership de Rust aide ici — une fois que tu as intériorisé le
pattern du « code sans allocations Box/Vec/String », le compilateur
te maintient honnête. Le pattern se transpose de projet en projet.
Surface FFI
Le moteur audio se compile en bibliothèque statique. L'app (dans mon cas React Native) appelle le moteur via une couche FFI. Deux choix de design qui comptent :
1. Garde la surface FFI petite. Chaque fonction FFI est une charge de maintenance — les deux langages doivent s'accorder sur le memory layout, la lifetime, la gestion d'erreurs. Je vise ~10-15 fonctions FFI qui wrappent l'API publique du moteur ; tout ce qui va au-delà reste interne côté Rust.
2. Passe des opaque pointers. N'essaie pas de partager des structs Rust
via l'ABI C. Alloue la struct en Rust, renvoie un pointeur
*mut OpaqueState, et fais en sorte que chaque appel FFI suivant repasse
ce pointeur. L'appelant ne regarde jamais à l'intérieur ; le côté Rust
possède le layout. Le cleanup est un seul appel FFI
drop_state(*mut OpaqueState).
Réalité cross-platform
Android AAudio se comporte différemment d'iOS CoreAudio. Des tailles de buffer qui fonctionnent sur un appareil ne fonctionnent pas sur un autre. Les builds Android OEM (Samsung, OnePlus, Xiaomi) ont chacun leurs cas limites. La réponse pratique :
- Épingle une version du NDK connue comme fonctionnelle
- Teste sur au moins trois appareils OEM, idéalement en incluant une puce d'entrée de gamme
- Build d'abord pour arm64 ; armv7 et x86_64 sont des dérivés mais doivent fonctionner au cas où un OEM les utilise
- Construis un chemin de fallback : si AAudio refuse la taille de buffer que tu demandes, reviens à la préférence de l'appareil et logue un warning
Un moteur audio correct en lui-même ne fonctionne pas pour autant sur tous les appareils. Un vrai banc de test compte plus que des benchmarks synthétiques.
Ce que cela rend possible
Dès que le chemin audio est sans allocation et le chemin de contrôle lock-free, tu peux empiler des couches : lecture multipiste, chaînes FX par piste, scheduling au sample près, contrôle MIDI. La discipline de base ne devient pas plus lourde, tu obtiens simplement plus de nodes dans le graphe.
La latence reste sous les 20ms sur du hardware Android grand public. C'est le seuil en dessous duquel la plupart des gens ressentent un effet « instantané ». Au-dessus de 20ms, tu sens le lag. En dessous de 20ms, tu te mesures aux DAW desktop sur le ressenti de base.