Three-tier AI fallback
Say your product calls an LLM API and that call fails. What does the user see? "Service temporarily unavailable" is the bad answer. The good answer: a quietly degraded response that still does what it's supposed to do, and that the user doesn't even notice.
The pattern is three tiers stacked: API → rule-based → hardcoded. Each tier can handle the same request, with declining quality but rising reliability.
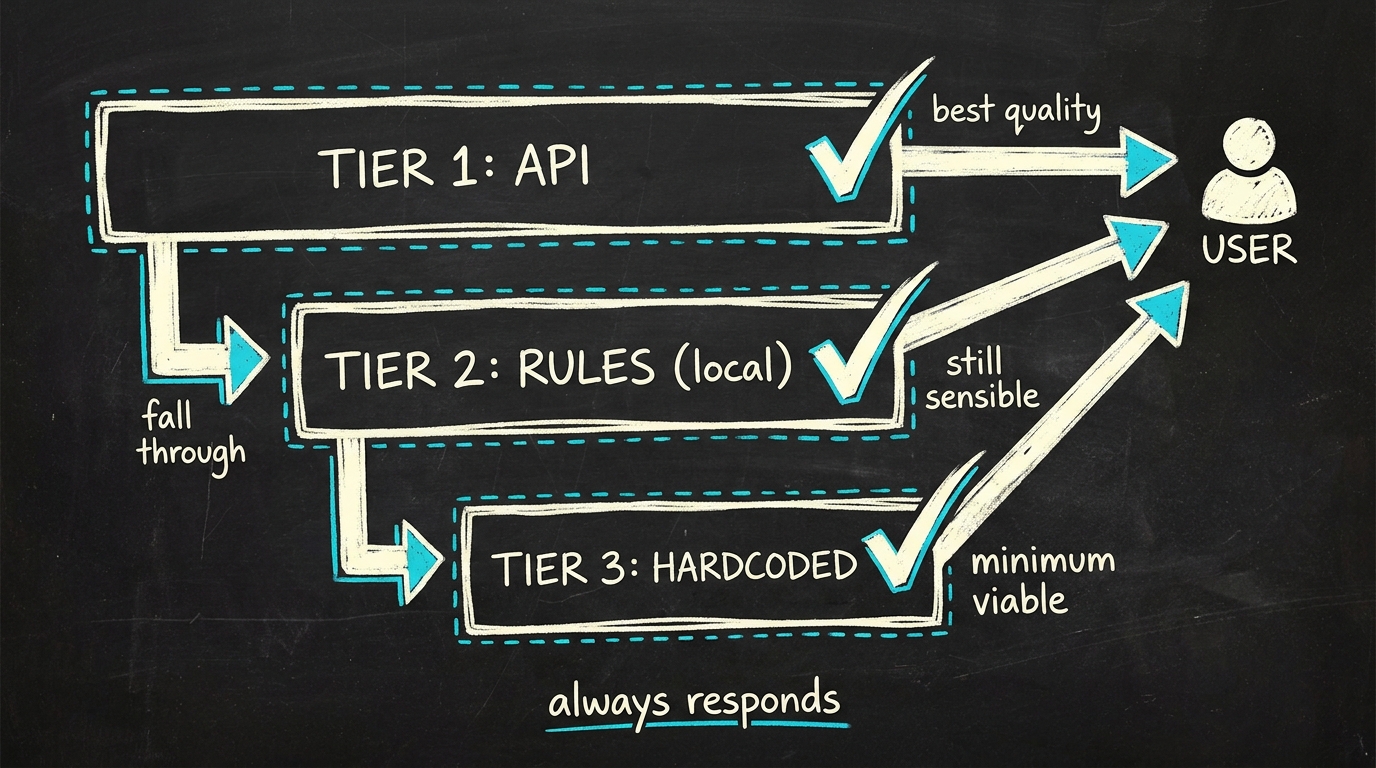
Whiteboard sketch · the cascade
The dispatch
async def generate_response(context: dict) -> str:
# Tier 1: LLM API (primary)
try:
return await _call_api(context, timeout=5.0)
except (httpx.HTTPError, APIError) as e:
log.info("tier-1 failed (%s), falling through", type(e).__name__)
# Tier 2: rule-based reasoning
try:
result = _rules_engine(context)
if result:
return result
except Exception as e:
log.warning("tier-2 failed (%s), falling through", e)
# Tier 3: hardcoded fallback
return _hardcoded_for_context(context)
The dispatch is deliberately dumb. Each tier returns either a usable response or nothing; and if it's nothing, the next one runs. No coordination, no retry logic at this level, no clever circuit breakers.
What each tier does
Tier 1 — LLM API is the default. Best output quality. But also the tier that fails when the network goes down, when you hit rate limits, when the provider has an incident, when your key rotates without warning, or when a model you rely on gets deprecated. Plan for all of those cases.
Tier 2 — rule-based reasoning runs the same logic, locally, in plain Python. For an AI coach that suggests input improvements: a handwritten rules engine with roughly 60 if/else branches covers the most common feedback patterns. Less elegant, but right 80% of the time and instant.
Tier 3 — hardcoded is the absolute minimum. A small dictionary of context-linked default answers. Boring, repetitive, but reliable. If both tier 1 and tier 2 fail, the user at least gets something, and something is always better than an error toast.
When to build tier 2 — and when not to
Tier 2 is, paradoxically, the most expensive tier to build — it's code, and writing code costs more time than an API call. You build it when:
- The feature sits in a critical user flow (every session hits it)
- "No response" is a visible break in the product
- The rules space is small enough to write out
You skip it when:
- The feature is rarely used or non-critical
- A failure can be resolved gracefully (a "try again" button)
- The rules space is genuinely open-ended (creative writing, for example)
For most features, tier 1 + tier 3 is enough. The middle tier is for products where reliability is part of the brand.
Cache is almost a tier of its own
Just below tier 1, before every call, a cache layer can skip the API
entirely. Cache keys are usually (context-hash, mood, last-action) or
something similar. A 40–60% hit rate is realistic for a chat agent with
recurring patterns.
Cache TTLs are a tuning problem, though. Too long and the agent "repeats itself" — users see the same answer twice in a session and the illusion breaks. Too short and you pay API costs you didn't have to. Start at 30 minutes and adjust based on complaints about repetition.
Observability per tier
Log which tier handled each request. After a week you'll see the real distribution. If tier 1 serves 99% and tier 2 + 3 together serve 1%, you can probably drop tier 2. If tier 2 comes in at 15%, it's pulling its weight — and your API is less reliable than you thought.
The numbers usually surprise you in at least one direction.
What it does for your brand
The biggest invisible win of this pattern: when other AI products fail visibly (toast errors, broken loading states, "AI is currently unavailable" banners), your product just keeps running. A little less smart, a little more boring, but still functional.
A user who has already been burned a few times by an AI product going down will come to trust yours — even if it, too, has been down ten times and they simply got tier-3 responses without noticing.