Fallback IA à trois niveaux
Imagine que ton produit appelle une API LLM et que cet appel échoue. Que voit l'utilisateur ? « Service temporarily unavailable », c'est la mauvaise réponse. La bonne réponse : une réponse discrètement dégradée qui fait quand même ce qu'elle doit faire, et que l'utilisateur ne remarque même pas.
Le schéma, ce sont trois niveaux empilés : API → règles → codé en dur. Chaque niveau peut traiter la même requête, avec une qualité décroissante mais une fiabilité croissante.
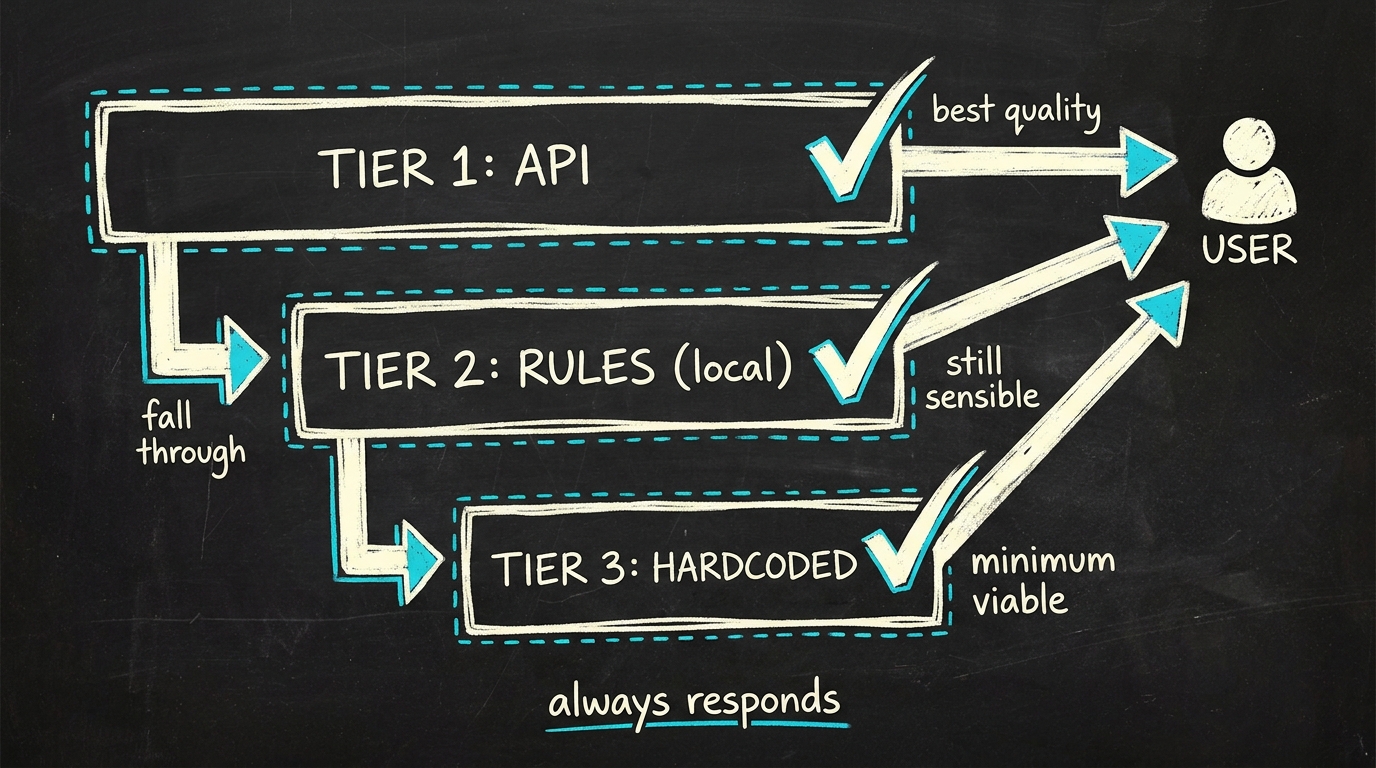
Croquis tableau blanc · la cascade
Le dispatch
async def generate_response(context: dict) -> str:
# Tier 1: LLM API (primaire)
try:
return await _call_api(context, timeout=5.0)
except (httpx.HTTPError, APIError) as e:
log.info("tier-1 failed (%s), falling through", type(e).__name__)
# Tier 2: rule-based reasoning
try:
result = _rules_engine(context)
if result:
return result
except Exception as e:
log.warning("tier-2 failed (%s), falling through", e)
# Tier 3: hardcoded fallback
return _hardcoded_for_context(context)
Le dispatch est volontairement bête. Chaque niveau renvoie soit une réponse exploitable, soit rien ; et si c'est rien, le niveau suivant s'exécute. Aucune coordination, aucune logique de retry à ce niveau, aucun circuit breaker malin.
Ce que fait chaque niveau
Niveau 1 — API LLM est l'option par défaut. La meilleure qualité de sortie. Mais aussi le niveau qui tombe quand le réseau lâche, quand tu atteins les limites de débit, quand le fournisseur a un incident, quand ta clé est tournée sans prévenir, ou quand un modèle sur lequel tu t'appuies devient deprecated. Prévois tous ces cas.
Niveau 2 — raisonnement par règles exécute la même logique, en local, en Python tout simple. Pour un coach AI qui propose des améliorations d'input : un moteur de règles écrit à la main avec environ 60 branches if/else couvre les schémas de feedback les plus courants. Moins élégant, mais juste 80 % du temps et instantané.
Niveau 3 — codé en dur est le strict minimum. Un petit dictionnaire de réponses par défaut liées au contexte. Ennuyeux, répétitif, mais fiable. Si le niveau 1 et le niveau 2 échouent, l'utilisateur reçoit au moins quelque chose, et quelque chose vaut toujours mieux qu'un toast d'erreur.
Quand mettre en place le niveau 2, et quand s'en passer
Le niveau 2 est, paradoxalement, le niveau le plus coûteux à construire — c'est du code, et écrire du code prend plus de temps qu'un appel d'API. Tu le construis quand :
- La fonctionnalité se trouve dans un user flow critique (chaque session la touche)
- « Aucune réponse » constitue une rupture visible dans le produit
- L'espace des règles est assez petit pour être écrit en entier
Tu t'en passes quand :
- La fonctionnalité est rarement utilisée ou non critique
- Un échec peut se résoudre élégamment (un bouton « réessayer »)
- L'espace des règles est vraiment ouvert (l'écriture créative, par exemple)
Pour la plupart des fonctionnalités, niveau 1 + niveau 3 suffisent. Le niveau intermédiaire est pour les produits où la fiabilité fait partie de la marque.
Le cache est presque un niveau à part entière
Juste sous le niveau 1, avant chaque appel, une couche de cache peut
contourner l'API entièrement. Les clés de cache sont en général
(context-hash, mood, last-action) ou quelque chose de similaire. Un taux
de hit de 40 à 60 % est réaliste pour un agent de chat aux schémas
récurrents.
Les TTL de cache restent toutefois un problème de tuning. Trop long et l'agent « se répète » — les utilisateurs voient deux fois la même réponse dans une session et l'illusion se brise. Trop court et tu paies des coûts d'API que tu n'avais pas à payer. Commence à 30 minutes et ajuste en fonction des plaintes sur la répétition.
Observabilité par niveau
Logue quel niveau a traité chaque requête. Au bout d'une semaine, tu verras la vraie distribution. Si le niveau 1 sert 99 % et que les niveaux 2 + 3 réunis servent 1 %, tu peux probablement supprimer le niveau 2. Si le niveau 2 atteint 15 %, il fait son travail — et ton API est moins fiable que tu ne le pensais.
Les chiffres te surprennent en général dans au moins une direction.
Ce que ça apporte à ta marque
Le plus grand gain invisible de ce schéma : quand d'autres produits AI échouent de manière visible (toasts d'erreur, états de chargement cassés, bannières « AI is currently unavailable »), ton produit continue simplement de tourner. Un peu moins malin, un peu plus ennuyeux, mais toujours fonctionnel.
Un utilisateur qui s'est déjà fait avoir plusieurs fois par un produit AI en panne finira par faire confiance au tien — même si lui aussi est tombé dix fois et qu'il a simplement reçu des réponses de niveau 3 sans s'en rendre compte.