ECHO — Agent-Orchestrator
Ein persönlicher, Jarvis-artiger Assistent, im Alleingang gebaut, lokal auf meiner eigenen Hardware laufend. Multi-Brain-LLM-Routing, Tool-Dispatch, Vault-gestütztes Gedächtnis, Filesystem-Watcher, dreistufiger KI-Fallback. Rund 24+ Python-Module im Orchestrator, dazu ein React/Vite-HUD, das alles in einem einzigen Dashboard sichtbar macht.
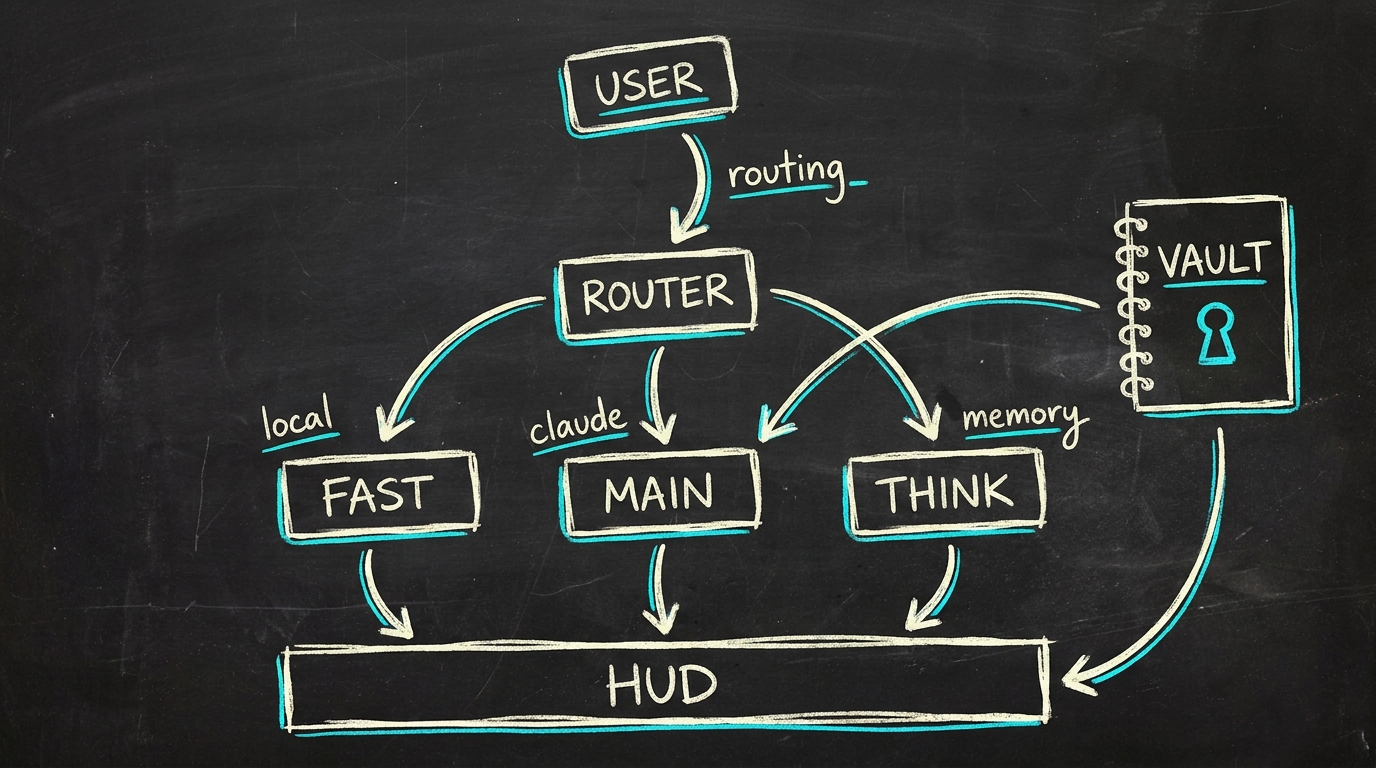
Whiteboard-Skizze · die Form des Systems
Was ECHO in der Praxis macht
Ich rede mit ihr, sie redet zurück. Aber das Interessante steckt nicht im Chat. Es steckt in dem, was zwischen den Turns passiert. ECHO beobachtet mein Dateisystem, die jüngsten Commits über all meine Projekte hinweg, die offenen Nudges in meinem Vault und synthetisiert das zu Morgen-Briefings, Code-Change-Chronicles, Time-Tracking-Aggregaten und proaktiven Eingriffen, wenn etwas nicht stimmt.
Konkret kann ECHO in einem einzigen Turn:
- Entscheiden, welchen Modell-Tier sie verwendet (
fast/main/think/local), basierend auf der Form der Anfrage - Ein Tool dispatchen (Vault-Suche, Datenbank-Query, Shell-Command, KPI-Puls eines angebundenen Produkts)
- Strukturiertes JSON für ein persönliches Dashboard aktualisieren
- Eine Notiz an einen laufenden Time-Entry hängen, ohne den Timer zu stoppen
- Einen Memory-Worker triggern, der die Daily-Note von gestern konsolidiert
Das HUD zeigt alles: einen „Brain Waves"-Trace, einen Token-Burn-Meter, einen Vault-Graph, einen CC-Status-Indikator und projektspezifische Panels (in dieser öffentlichen Version teilweise redigiert).
Architektur
┌─────────────────────────────────────────────────────────────┐
│ HUD (React + Vite) │
│ Presence · Vitals · TokenBurn · VaultGraph · Project │
│ panels · RailTabs · Identity │
└──────────────────────────────┬──────────────────────────────┘
│ HTTP polling + SSE
▼
┌─────────────────────────────────────────────────────────────┐
│ Orchestrator (FastAPI · Python 3.13) │
│ ───────────────────────────────────────────────────────── │
│ router.py — Multi-brain selection (heuristics + LLM) │
│ tools.py — 14+ tool dispatch │
│ skills.py — agentskills.io-compatible workflow layer │
│ vault_graph.py — Markdown vault + Wikilink edges │
│ time_track.py — Time entries, Stundenkriterium, exports │
│ runway.py — Personal-finance runway dashboard │
│ social.py — Social-media accounts registry │
│ cc_status.py — Claude Code activity from JSONL │
│ ... + nudges, agenda, hue, intents, voice, tts, und eine │
│ Handvoll produktspezifischer Integrationsmodule │
└──────┬──────────────────────────────┬───────────────────────┘
│ │
▼ ▼
┌──────────────────┐ ┌────────────────────────────────┐
│ Memory Worker │ │ External LLMs │
│ (APScheduler) │ │ ───────────────────────────── │
│ ────────────── │ │ Anthropic (Claude API) │
│ Drafter │ │ Ollama local (Qwen, Llama) │
│ Curator │ │ ComfyUI local (Stable Diff) │
│ Consolidator │ │ │
│ Watchers │ │ 3-tier fallback: │
│ Reflector │ │ API → rules → hardcoded │
│ Daily-summary │ │ │
└──────────────────┘ └────────────────────────────────┘
Der Multi-Brain-Router
Der Router bestimmt, welcher Modell-Tier angesprochen wird, bevor die Anfrage den Orchestrator verlässt. Erst günstige Heuristiken, dann erst ein LLM-Classifier, wenn diese es nicht wissen.
async def decide(text: str, *, force: Brain | None = None) -> RouterDecision:
if force is not None:
return RouterDecision(force, "manual", "user-override")
# Günstige Regex-Heuristiken zuerst
h = _heuristic(text)
if h is not None:
return h
# Fallback auf ein kleines Modell als Classifier
return await _llm_classify(text)
Vier Heuristik-Schichten laufen der Reihe nach: Trivial-Gruß
(Sub-Sekunden-Antworten gehen an fast), Business-Keyword (alles, was
einen Projektkontext berührt, geht an main, damit der richtige
System-Prompt lädt), Deep-Keyword (Architektur / Code-Review an
think) und Shell-Keyword (Dateisystem-Fragen an main, wo
Shell-Tools verfügbar sind).
Diese letzte Schicht leistet mehr, als man denkt: kleine Modelle
schreiben PowerShell-Commands routinemäßig als Markdown-Block aus,
statt das Shell-Tool aufzurufen. Diese Queries an main zu routen,
behebt die Failure-Mode an der Wurzel.
Tool-Dispatch + Skills-Schicht
ECHO bietet ~14 Tools über das Tool-Use-Protokoll an:
vault_read, vault_search, shell_check, list_skills /
run_skill, time_start / time_stop, time_summary,
note_learning und eine Handvoll produktspezifischer Tools.
Die Skills-Schicht ist agentskills.io-kompatibel: jeder Skill liegt
unter memory/_skills/<skill-name>/SKILL.md mit YAML-Frontmatter für
Metadaten und einem Markdown-Body für das Rezept. list_skills ist
günstig (liefert nur Frontmatter); run_skill(name) lädt den
vollständigen Body und ECHO folgt den nummerierten Schritten, ruft die
Tools in der richtigen Reihenfolge auf.
Invocation-Count, Success-Rate und Last-Used-Timestamp aktualisieren sich selbst im Frontmatter. Träge Telemetrie, keine separate Datenbank.
Vault-gestütztes Gedächtnis
Das Gedächtnis von ECHO ist ein Markdown-Vault mit WikiLink-Edges. Der
Vault hat Ordner für People, Projects, Daily-Notes, Knowledge, Tasks
und System. Der Graph wird live von vault_graph.py geparst und im HUD
als 3D-force-directed-Visualisierung mit Ordner-Clustering gerendert.
Was im Vault lebt: meine eigenen Notizen, eine Inbox, in die ECHO
vorgeschlagene Nudges ablegt, Daily-Notes, die der Consolidator
schreibt, eine Chronicle jedes Claude-Code-Commits über all meine
Projekte hinweg und ein CC-inbox.md-Kanal, über den Dev-Claude ECHO
zwischen Turns briefen kann.
Die Watcher — Python-Jobs, von APScheduler gescheduled — überwachen Commits, Sentry, Issues, Projekt-State, Agenda, Idle. Jeder emittiert einen strukturierten Trigger, wenn er etwas sieht, das ECHO's Aufmerksamkeit wert ist; der Drafter macht aus Triggern Proposed Nudges; der Curator aggregiert periodisch.
Dreistufiger KI-Fallback
ECHO nimmt nie an, dass die API verfügbar ist. Drei Tiers:
- Tier 1 — API (primär, höchste Qualität)
- Tier 2 — Rule-based Reasoning (Fallback, wenn die API down oder rate-limited ist; weniger flüssig, aber immer noch sinnvoll)
- Tier 3 — Hardcoded (Offline-Minimum-Viable-Response)
Dieses Muster taucht über mehrere Schichten hinweg auf. Das Ergebnis: ECHO funktioniert weiter, auch wenn externe Dienste das nicht tun.
Lokale KI-Infrastruktur
ECHO läuft lokal auf meinem Haupt-Arbeitsplatz: Ryzen 7 3700X mit AMD RX 6650 XT (8GB), Windows. Der Orchestrator, das HUD, der Vault, die Watcher und Drafter sowie ComfyUI für die Image-Generation laufen alle auf derselben Box. Eine ältere AMD-Maschine steht daneben als Linux-Testbed für Side-Projects, nicht als Teil des produktiven ECHO-Pfads.
Für schwerere Inferenz (größere Context-Windows, Modell-Fine-Tuning, Batch-Image-Arbeit) greife ich auf Remote-Zugriff auf ein leistungsfähigeres GPU-Setup über TeamViewer oder einen direkten Port-Forward zurück.
Lokale LLMs laufen über Ollama (Qwen 2.5 7B, Llama 3.2 3B) für Routing, Klassifikation und alles, wo die API nicht nötig ist. Die Anthropic Claude API ist für komplexe Reasoning-Arbeit reserviert, bei der lokale Modelle die Qualität nicht erreichen. Der Großteil der Routine-Arbeit läuft auf der Haupt-Box; die Cloud-Kosten bleiben bescheiden.
Privacy-Filter
Der Vault wird in jedem Turn in ECHO's Persona geladen. Alles, was darin steht, wird also vom LLM gelesen und an die API geschickt. Ein Privacy-Filter läuft an jedem Write-Entry-Point (Drafter, Curator, Extractor, Commit-Chronicles, Daily-Summarizer) und redigiert eine kleine Menge lokal sensibler Programmnamen zu einem generischen Token. Filter auf der Write-Seite; die Read-Seite bleibt simpel.
Autonome Schichten
ECHO ist in Schichten aufgebaut, jede progressiv autonomer:
- Gedächtnis-Schicht — Obsidian-Vault mit WikiLink-Edges, gespeist von jedem Gespräch, jeder Entscheidung und jedem Commit. Markdown, kein Lock-in, unabhängig von ECHO lesbar.
- Watcher — Python-Jobs auf APScheduler, die Filesystem-Events, Git-Commits, Calendar-Pings und Sentry-Issues überwachen und strukturierte Trigger emittieren.
- Drafter — Cron-Jobs für Weekly Recap, Daily Summary, Time-Tracking-Aggregat und Vault-Consolidation. Der Output landet als Proposed Nudges in einer Inbox zur Durchsicht.
- Sleep-Time-Compute (in Entwicklung) — günstiges Modell, das nachts neue Vault-Entries liest und Verbindungen vorschlägt.