ECHO — orchestrateur d'agents
Un assistant personnel à la Jarvis, conçu en solo, tournant en local sur mon propre matériel. Routage LLM multi-brain, dispatch d'outils, mémoire adossée à un vault, filesystem-watchers, fallback IA à trois niveaux. Environ 24+ modules Python dans l'orchestrateur, plus un HUD React/Vite qui fait remonter tout dans un seul tableau de bord.
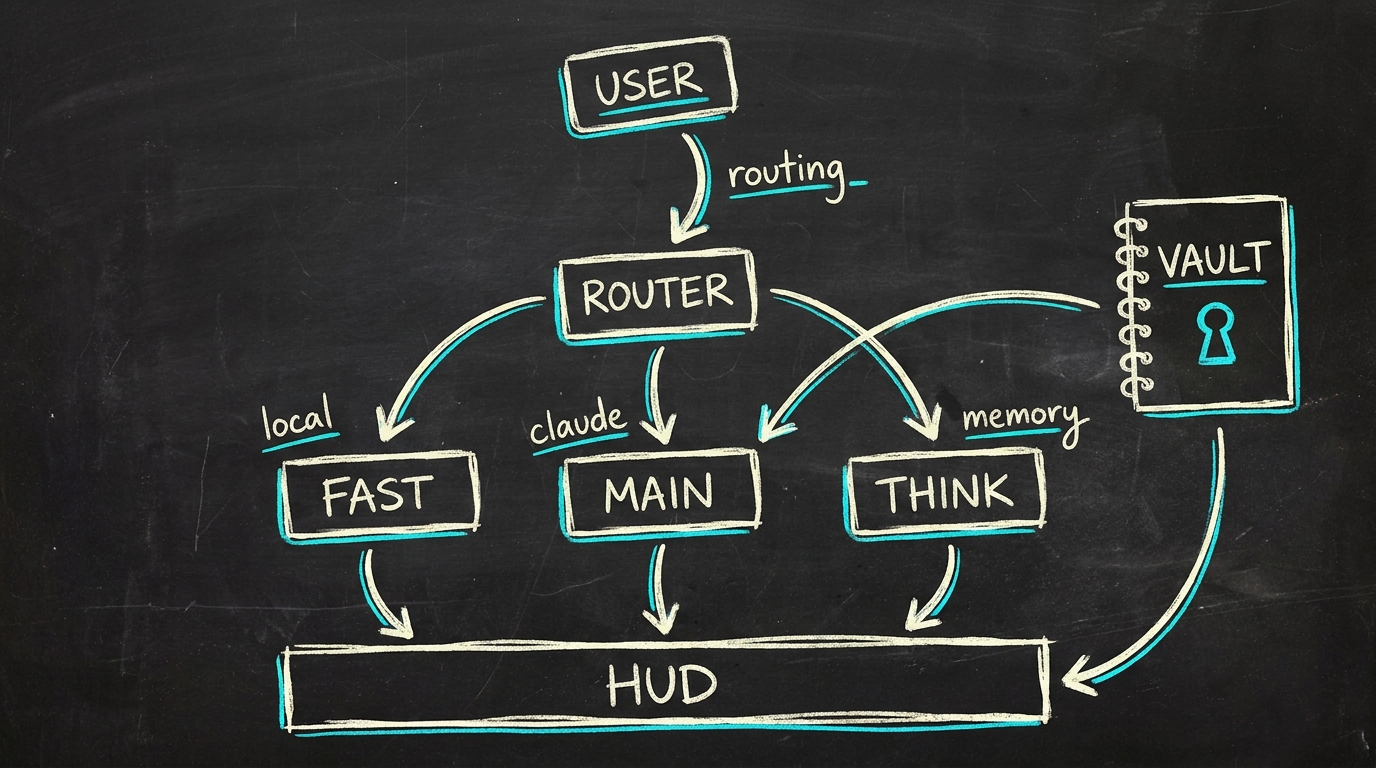
Croquis de whiteboard · la forme du système
Ce qu'ECHO fait en pratique
Je lui parle, elle me répond. Mais l'intéressant n'est pas dans le chat. C'est dans ce qui se passe entre les tours. ECHO observe mon système de fichiers, les commits récents sur l'ensemble de mes projets, les nudges ouverts dans mon vault, et synthétise tout cela en briefings matinaux, en chroniques de changements de code, en agrégats de time-tracking, et en interventions proactives quand quelque chose cloche.
Concrètement, en un seul tour, ECHO peut :
- Décider quel tier de modèle utiliser (
fast/main/think/local) selon la forme de la requête - Dispatcher un outil (vault-search, requête base de données, commande shell, pouls de KPI d'un produit connecté)
- Mettre à jour du JSON structuré pour un tableau de bord personnel
- Attacher une note à une entrée de temps en cours sans arrêter le timer
- Déclencher un memory-worker qui consolide la daily-note d'hier
Le HUD montre tout : une trace « Brain Waves », un compteur de token-burn, un graphe de vault, un indicateur de statut CC, et des panneaux spécifiques aux projets (en partie expurgés dans cette version publique).
Architecture
┌─────────────────────────────────────────────────────────────┐
│ HUD (React + Vite) │
│ Presence · Vitals · TokenBurn · VaultGraph · Project │
│ panels · RailTabs · Identity │
└──────────────────────────────┬──────────────────────────────┘
│ HTTP polling + SSE
▼
┌─────────────────────────────────────────────────────────────┐
│ Orchestrator (FastAPI · Python 3.13) │
│ ───────────────────────────────────────────────────────── │
│ router.py — Multi-brain selection (heuristics + LLM) │
│ tools.py — 14+ tool dispatch │
│ skills.py — agentskills.io-compatible workflow layer │
│ vault_graph.py — Markdown vault + Wikilink edges │
│ time_track.py — Time entries, critère horaire, exports │
│ runway.py — Personal-finance runway dashboard │
│ social.py — Social-media accounts registry │
│ cc_status.py — Claude Code activity from JSONL │
│ ... + nudges, agenda, hue, intents, voice, tts, et une │
│ poignée de modules d'intégration propres aux produits │
└──────┬──────────────────────────────┬───────────────────────┘
│ │
▼ ▼
┌──────────────────┐ ┌────────────────────────────────┐
│ Memory Worker │ │ External LLMs │
│ (APScheduler) │ │ ───────────────────────────── │
│ ────────────── │ │ Anthropic (Claude API) │
│ Drafter │ │ Ollama local (Qwen, Llama) │
│ Curator │ │ ComfyUI local (Stable Diff) │
│ Consolidator │ │ │
│ Watchers │ │ 3-tier fallback: │
│ Reflector │ │ API → rules → hardcoded │
│ Daily-summary │ │ │
└──────────────────┘ └────────────────────────────────┘
Le router multi-brain
Le router détermine quel tier de modèle est sollicité avant que la requête ne quitte l'orchestrateur. D'abord des heuristiques bon marché, puis seulement un classifieur LLM si elles ne savent pas trancher.
async def decide(text: str, *, force: Brain | None = None) -> RouterDecision:
if force is not None:
return RouterDecision(force, "manual", "user-override")
# Heuristiques regex bon marché d'abord
h = _heuristic(text)
if h is not None:
return h
# Fallback sur un petit modèle comme classifieur
return await _llm_classify(text)
Quatre couches d'heuristiques s'exécutent dans l'ordre :
salutation-triviale (les réponses sous la seconde vont vers fast),
business-keyword (tout ce qui touche un contexte de projet va vers
main pour que le bon system-prompt se charge), deep-keyword
(architecture / code-review vers think), et shell-keyword (les
questions sur le système de fichiers vers main, là où les outils
shell sont disponibles).
Cette dernière couche fait plus qu'on ne le croit : les petits modèles
écrivent régulièrement des commandes PowerShell sous forme de bloc
Markdown au lieu d'appeler l'outil shell. Router ces requêtes vers
main corrige la failure-mode à la source.
Dispatch d'outils + couche de skills
ECHO propose ~14 outils via le protocole tool-use :
vault_read, vault_search, shell_check, list_skills /
run_skill, time_start / time_stop, time_summary,
note_learning, et une poignée d'outils propres aux produits.
La couche de skills est compatible agentskills.io : chaque skill vit
dans memory/_skills/<skill-name>/SKILL.md avec un frontmatter YAML
pour les métadonnées et un corps Markdown pour la recette. list_skills
est bon marché (ne retourne que le frontmatter) ; run_skill(name)
charge le corps complet et ECHO suit les étapes numérotées, appelant
les outils dans le bon ordre.
Le compteur d'invocations, le taux de réussite et le timestamp de dernière utilisation se mettent à jour eux-mêmes dans le frontmatter. Télémétrie lente, pas de base de données séparée.
Mémoire adossée à un vault
La mémoire d'ECHO est un vault Markdown avec des edges WikiLink. Le
vault a des dossiers pour People, Projects, Daily-notes, Knowledge,
Tasks et System. Le graphe est parsé en direct par vault_graph.py et
rendu dans le HUD sous forme de visualisation 3D force-directed avec
clustering par dossier.
Ce qui vit dans le vault : mes propres notes, une inbox où ECHO dépose
des nudges proposés, des daily-notes que le consolidator écrit, une
chronique de chaque commit Claude Code sur l'ensemble de mes projets,
et un canal CC-inbox.md où dev-Claude peut briefer ECHO entre les
tours.
Les watchers — des jobs Python schedulés par APScheduler — surveillent les commits, sentry, les issues, l'état des projets, l'agenda, l'idle. Chacun émet un trigger structuré quand il voit quelque chose digne de l'attention d'ECHO ; le drafter transforme les triggers en nudges proposés ; le curator agrège périodiquement.
Fallback IA à trois niveaux
ECHO ne suppose jamais que l'API est disponible. Trois niveaux :
- Tier 1 — API (primaire, qualité maximale)
- Tier 2 — Raisonnement à base de règles (fallback si l'API est down ou rate-limited ; moins fluide, mais toujours pertinent)
- Tier 3 — Hardcodé (réponse minimale viable hors ligne)
Ce schéma se retrouve sur plusieurs couches. Résultat : ECHO continue de fonctionner même quand les services externes ne le font pas.
Infrastructure IA locale
ECHO tourne en local sur mon poste de travail principal : Ryzen 7 3700X avec une AMD RX 6650 XT (8 Go), Windows. L'orchestrateur, le HUD, le vault, les watchers et drafters, et ComfyUI pour la génération d'images tournent tous sur la même machine. Une machine AMD plus ancienne se trouve à côté comme banc de test Linux pour des side-projects, et non comme partie du chemin de production d'ECHO.
Pour de l'inférence plus lourde (fenêtres de contexte plus grandes, fine-tuning de modèle, traitement d'images en batch), je me rabats sur un accès distant à une configuration GPU plus capable via TeamViewer ou un port-forward direct.
Les LLM locaux tournent via Ollama (Qwen 2.5 7B, Llama 3.2 3B) pour le routage, la classification, et tout ce où l'API n'est pas nécessaire. L'API Anthropic Claude est réservée au raisonnement complexe où les modèles locaux n'atteignent pas la qualité requise. L'essentiel du travail de routine tourne sur la machine principale ; les coûts cloud restent modestes.
Filtre de confidentialité
Le vault est chargé dans la persona d'ECHO à chaque tour. Tout ce qui s'y trouve est donc lu par le LLM et envoyé à l'API. Un filtre de confidentialité s'exécute à chaque point d'entrée d'écriture (drafter, curator, extractor, commit-chronicles, daily-summarizer) et expurge un petit ensemble de noms de programmes sensibles localement en un token générique. Filtre du côté écriture ; le côté lecture reste simple.
Couches autonomes
ECHO est construit en couches, chacune progressivement plus autonome :
- Couche de mémoire — un vault Obsidian avec des edges WikiLink, alimenté par chaque conversation, décision et commit. Markdown, pas de lock-in, lisible indépendamment d'ECHO.
- Watchers — des jobs Python sur APScheduler qui surveillent les événements du système de fichiers, les commits git, les pings de calendrier et les issues sentry, et émettent des triggers structurés.
- Drafters — des cron-jobs pour le récap hebdomadaire, le résumé quotidien, l'agrégat de time-tracking et la consolidation du vault. La sortie atterrit sous forme de nudges proposés dans une inbox pour relecture.
- Sleep-time-compute (en cours de développement) — un modèle bon marché qui lit la nuit les nouvelles entrées du vault et propose des liens.