ECHO — agent orchestrator
A personal, Jarvis-like assistant, built solo, running locally on my own hardware. Multi-brain LLM routing, tool dispatch, vault-backed memory, filesystem watchers, three-tier AI fallback. Roughly 24+ Python modules in the orchestrator, plus a React/Vite HUD that surfaces everything in a single dashboard.
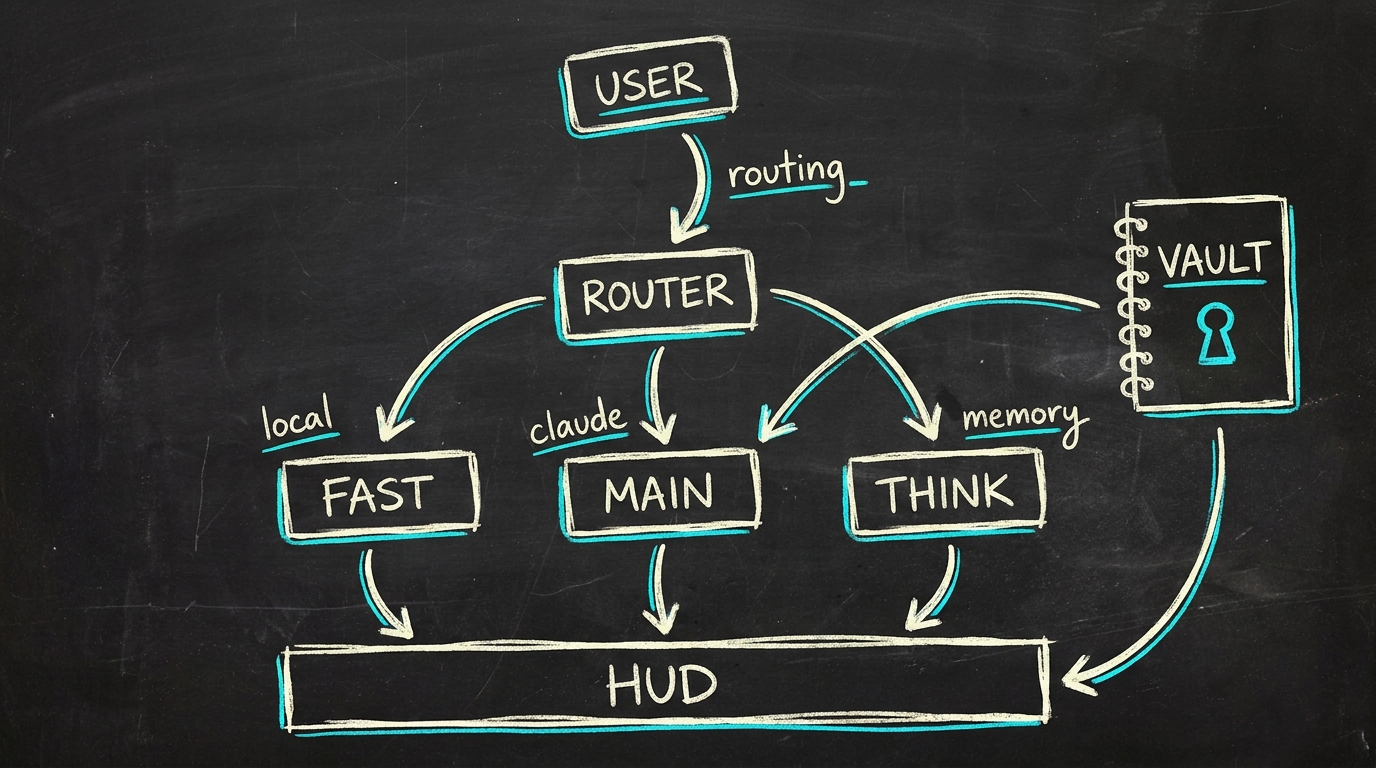
Whiteboard sketch · the shape of the system
What ECHO does in practice
I talk to her, she talks back. But the interesting part isn't in the chat. It's in what happens between turns. ECHO observes my filesystem, the recent commits across all my projects, the open nudges in my vault, and synthesizes that into morning briefings, code-change chronicles, time-tracking aggregates, and proactive interventions when something is off.
Concretely, in a single turn ECHO can:
- Decide which model tier to use (
fast/main/think/local) based on the shape of the request - Dispatch a tool (vault search, database query, shell command, KPI pulse from a connected product)
- Update structured JSON for a personal dashboard
- Attach a note to a running time entry without stopping the timer
- Trigger a memory worker that consolidates yesterday's daily note
The HUD shows everything: a "Brain Waves" trace, a token-burn meter, a vault graph, a CC status indicator, and project-specific panels (partly redacted in this public version).
Architecture
┌─────────────────────────────────────────────────────────────┐
│ HUD (React + Vite) │
│ Presence · Vitals · TokenBurn · VaultGraph · Project │
│ panels · RailTabs · Identity │
└──────────────────────────────┬──────────────────────────────┘
│ HTTP polling + SSE
▼
┌─────────────────────────────────────────────────────────────┐
│ Orchestrator (FastAPI · Python 3.13) │
│ ───────────────────────────────────────────────────────── │
│ router.py — Multi-brain selection (heuristics + LLM) │
│ tools.py — 14+ tool dispatch │
│ skills.py — agentskills.io-compatible workflow layer │
│ vault_graph.py — Markdown vault + Wikilink edges │
│ time_track.py — Time entries, hours criterion, exports │
│ runway.py — Personal-finance runway dashboard │
│ social.py — Social-media accounts registry │
│ cc_status.py — Claude Code activity from JSONL │
│ ... + nudges, agenda, hue, intents, voice, tts, and a │
│ handful of product-specific integration modules │
└──────┬──────────────────────────────┬───────────────────────┘
│ │
▼ ▼
┌──────────────────┐ ┌────────────────────────────────┐
│ Memory Worker │ │ External LLMs │
│ (APScheduler) │ │ ───────────────────────────── │
│ ────────────── │ │ Anthropic (Claude API) │
│ Drafter │ │ Ollama local (Qwen, Llama) │
│ Curator │ │ ComfyUI local (Stable Diff) │
│ Consolidator │ │ │
│ Watchers │ │ 3-tier fallback: │
│ Reflector │ │ API → rules → hardcoded │
│ Daily-summary │ │ │
└──────────────────┘ └────────────────────────────────┘
The multi-brain router
The router decides which model tier gets called before the request leaves the orchestrator. Cheap heuristics first, and only then an LLM classifier if those can't tell.
async def decide(text: str, *, force: Brain | None = None) -> RouterDecision:
if force is not None:
return RouterDecision(force, "manual", "user-override")
# Cheap regex heuristics first
h = _heuristic(text)
if h is not None:
return h
# Fall back to a small model as classifier
return await _llm_classify(text)
Four heuristic layers run in order: trivial-greeting (sub-second
responses go to fast), business-keyword (anything that touches a
project context goes to main so the right system prompt loads),
deep-keyword (architecture / code review to think), and
shell-keyword (filesystem questions to main where shell tools are
available).
That last layer does more than you'd think: small models routinely
write out PowerShell commands as a Markdown block instead of calling
the shell tool. Routing those queries to main fixes the failure
mode at the source.
Tool dispatch + skills layer
ECHO exposes ~14 tools through the tool-use protocol:
vault_read, vault_search, shell_check, list_skills /
run_skill, time_start / time_stop, time_summary,
note_learning, and a handful of product-specific tools.
The skills layer is agentskills.io-compatible: each skill lives at
memory/_skills/<skill-name>/SKILL.md with YAML frontmatter for
metadata and a Markdown body for the recipe. list_skills is cheap
(returns only frontmatter); run_skill(name) loads the full body and
ECHO follows the numbered steps, calling the tools in the right
order.
Invocation count, success rate, and last-used timestamp update themselves in the frontmatter. Slow telemetry, no separate database.
Vault-backed memory
ECHO's memory is a Markdown vault with WikiLink edges. The vault
has folders for People, Projects, Daily notes, Knowledge, Tasks, and
System. The graph is parsed live by vault_graph.py and rendered in
the HUD as a 3D force-directed visualization with folder clustering.
What lives in the vault: my own notes, an inbox where ECHO drops
proposed nudges, daily notes that the consolidator writes, a
chronicle of every Claude Code commit across all my projects, and
a CC-inbox.md channel where dev-Claude can brief ECHO between turns.
The watchers — Python jobs scheduled by APScheduler — monitor commits, sentry, issues, project state, agenda, idle. Each emits a structured trigger when it sees something worthy of ECHO's attention; the drafter turns triggers into proposed nudges; the curator aggregates periodically.
Three-tier AI fallback
ECHO never assumes the API is up. Three tiers:
- Tier 1 — API (primary, highest quality)
- Tier 2 — Rule-based reasoning (fallback if the API is down or rate-limited; less fluent, but still sensible)
- Tier 3 — Hardcoded (offline minimum-viable response)
This pattern recurs across multiple layers. The result: ECHO keeps working even when external services don't.
Local AI infrastructure
ECHO runs locally on my main workstation: Ryzen 7 3700X with an AMD RX 6650 XT (8GB), Windows. The orchestrator, the HUD, the vault, the watchers and drafters, and ComfyUI for image generation all run on the same box. An older AMD machine sits next to it as a Linux testbed for side projects, not as part of the production ECHO path.
For heavier inference (larger context windows, model fine-tuning, batch image work) I fall back on remote access to a more capable GPU setup via TeamViewer or a direct port forward.
Local LLMs run through Ollama (Qwen 2.5 7B, Llama 3.2 3B) for routing, classification, and anything where the API isn't needed. The Anthropic Claude API is reserved for complex reasoning where local models can't match the quality. Most routine work runs on the main box; cloud costs stay modest.
Privacy filter
The vault is loaded into ECHO's persona on every turn. So everything in it gets read by the LLM and sent to the API. A privacy filter runs on every write entry point (drafter, curator, extractor, commit chronicles, daily summarizer) and redacts a small set of locally sensitive program names to a generic token. Filter on the write side; the read side stays simple.
Autonomous layers
ECHO is built in layers, each progressively more autonomous:
- Memory layer — an Obsidian vault with WikiLink edges, fed by every conversation, decision and commit. Markdown, no lock-in, readable independently of ECHO.
- Watchers — Python jobs on APScheduler that monitor filesystem events, git commits, calendar pings and sentry issues and emit structured triggers.
- Drafters — cron jobs for weekly recap, daily summary, time-tracking aggregate and vault consolidation. Output lands as proposed nudges in an inbox for review.
- Sleep-time compute (in development) — a cheap model that reads new vault entries at night and proposes connections.